Langchain Expression Language - AIShorts #2
A Brand new series where I break down AI, GenAI, and Agents one concept at a time. Whether it's daily or weekly, you get insights so you can keep up with the ever-evolving world of AI.

🚀 Tired of Debugging Spaghetti Chains? Meet LangChain Expression Language (LCEL)
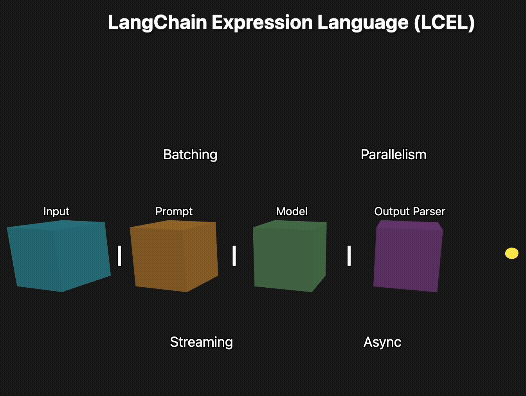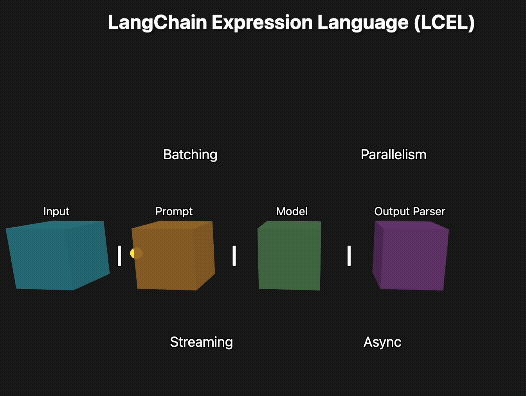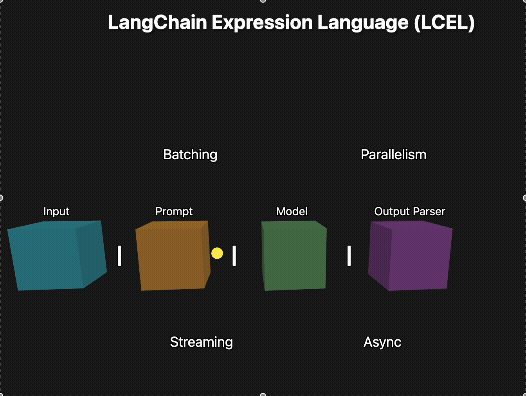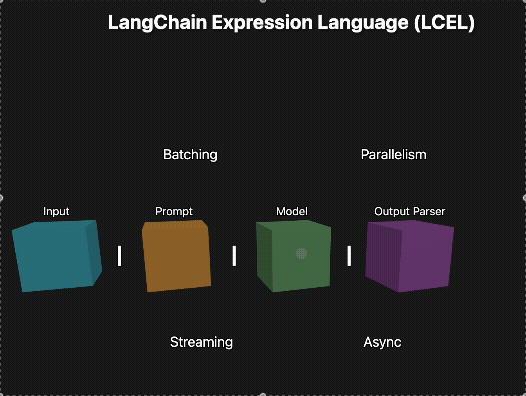
You've built your LangChain application. Now the real question is - how quickly can you scale when you need composable, maintainable chains that can handle complex workflows and streaming responses?
Too many LangChain apps start small and then collapse into a tangle of nested callbacks and undocumented state once you bolt on retrieval, memory, and streaming. Latency creeps up, errors become opaque, and every new feature feels like surgery.
LCEL fixes this by promoting each step to a first-class Runnable and giving you a declarative pipe syntax (|) to compose them.
That means:
Run steps in parallel or async with no extra code
Stream answers right away
See every step in LangSmith
If you're wrestling with fragile, slow chains, LCEL is the escape hatch. (Full concept guide ➜ LCEL docs).
This guide walks through practical workflows for implementing LangChain Expression Language (LCEL), with real examples and configuration snippets. The focus is on simple setups you can build on, with notes on how to scale them for production environments.
TL;DR
LCEL uses a simple
|symbol to build clear chains.Mix steps (sequential, parallel, conditional) without the mess.
Use async streaming and batch calls to keep it fast.
Add fallbacks, retries, and basic metrics so your app keeps working.
Ship with FastAPI and grow with Docker and Kubernetes.
Step-by-Step: Setting Up LCEL for Production Chains
1. Define Your Chain Architecture
Focus on two areas:
Chain Composition Patterns
Sequential chains for step-by-step processing
Parallel chains for concurrent operations
Conditional chains for dynamic routing
Streaming chains for real-time responses
Data Flow Management
Input validation and transformation
Output parsing and formatting
Error handling and fallbacks
State management across chain steps
2. Install and Configure LangChain LCEL
Start with the core LangChain installation:
pip install langchain langchain-openai langchain-community
# Basic LCEL chain setup
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# Simple chain composition
prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
model = ChatOpenAI(model="gpt-3.5-turbo")
output_parser = StrOutputParser()
# LCEL chain using pipe operator
chain = prompt | model | output_parser
# Execute the chain
result = chain.invoke({"topic": "programming"})
print(result)
For more complex chain composition:
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.prompts import PromptTemplate
# Multi-step chain with parallel processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Retrieval chain
retriever = vectorstore.as_retriever()
# Parallel processing chain
rag_chain = (
RunnableParallel({
"context": retriever | format_docs,
"question": RunnablePassthrough()
})
| ChatPromptTemplate.from_template(
"Answer the question based on context:\n{context}\n\nQuestion: {question}"
)
| model
| StrOutputParser()
)
# Execute with streaming
for chunk in rag_chain.stream({"question": "What is machine learning?"}):
print(chunk, end="", flush=True)
💡 Pro tip: Use LCEL's pipe operator (|) for readable chain composition and leverage RunnableParallel for concurrent operations to improve performance.
3. Implement Advanced Chain Patterns
Set up conditional routing and dynamic chains:
from langchain_core.runnables import RunnableBranch, RunnableLambda
# Conditional chain routing
def route_question(x):
if "code" in x["question"].lower():
return "coding"
elif "math" in x["question"].lower():
return "math"
else:
return "general"
# Branch-based routing
routing_chain = RunnableBranch(
(
lambda x: route_question(x) == "coding",
ChatPromptTemplate.from_template(
"You are a coding expert. Answer this programming question: {question}"
) | model | StrOutputParser()
),
(
lambda x: route_question(x) == "math",
ChatPromptTemplate.from_template(
"You are a math tutor. Solve this problem step by step: {question}"
) | model | StrOutputParser()
),
# Default route
ChatPromptTemplate.from_template(
"Answer this general question: {question}"
) | model | StrOutputParser()
)
# Execute routing chain
result = routing_chain.invoke({"question": "How do I implement a binary search?"})
Implement chain with memory and state management:
from langchain.memory import ConversationBufferMemory
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
# Stateful conversation chain
def get_session_history(session_id: str) -> ChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
store = {}
conversational_chain = RunnableWithMessageHistory(
prompt | model | StrOutputParser(),
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
# Use with session management
response = conversational_chain.invoke(
{"input": "Hi, I'm working on a Python project"},
config={"configurable": {"session_id": "user123"}}
)
4. Configure Streaming and Async Operations
Set up streaming responses for real-time applications:
import asyncio
from langchain_core.callbacks import AsyncCallbackHandler
class StreamingCallbackHandler(AsyncCallbackHandler):
def __init__(self):
self.tokens = []
async def on_llm_new_token(self, token: str, **kwargs):
self.tokens.append(token)
print(token, end="", flush=True)
# Async streaming chain
async def stream_chain_response(question: str):
callback_handler = StreamingCallbackHandler()
async_chain = (
prompt
| model.with_config(callbacks=[callback_handler])
| StrOutputParser()
)
result = await async_chain.ainvoke({"topic": question})
return result
# Execute async streaming
asyncio.run(stream_chain_response("artificial intelligence"))
Implement batch processing for high-throughput scenarios:
# Batch processing with LCEL
questions = [
{"topic": "machine learning"},
{"topic": "data science"},
{"topic": "artificial intelligence"},
{"topic": "deep learning"}
]
# Batch invoke
results = chain.batch(questions, config={"max_concurrency": 4})
# Async batch processing
async def process_batch_async(questions):
results = await chain.abatch(questions, config={"max_concurrency": 8})
return results
batch_results = asyncio.run(process_batch_async(questions))
💡 Production consideration: Use async operations and batch processing for high-throughput applications, and implement proper error handling with retry logic.
5. Implement Error Handling and Fallbacks
Set up robust error handling:
from langchain_core.runnables import RunnableWithFallbacks
from langchain_core.exceptions import OutputParserException
# Fallback chain configuration
primary_chain = prompt | model | StrOutputParser()
# Fallback model
fallback_model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.1)
fallback_chain = prompt | fallback_model | StrOutputParser()
# Chain with fallbacks
robust_chain = RunnableWithFallbacks(
runnable=primary_chain,
fallbacks=[fallback_chain]
)
# Custom error handling
def handle_parsing_error(error):
return f"Error parsing response: {str(error)}"
safe_chain = (
prompt
| model
| StrOutputParser().with_fallbacks([
RunnableLambda(handle_parsing_error)
])
)
Implement retry logic and circuit breakers:
import time
from functools import wraps
def retry_with_backoff(max_retries=3, backoff_factor=2):
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
return await func(*args, **kwargs)
except Exception as e:
if attempt == max_retries - 1:
raise e
wait_time = backoff_factor ** attempt
await asyncio.sleep(wait_time)
return None
return wrapper
return decorator
@retry_with_backoff(max_retries=3)
async def invoke_chain_with_retry(chain, input_data):
return await chain.ainvoke(input_data)
6. Set Up Monitoring and Observability
Implement comprehensive chain monitoring:
from langchain.callbacks import StdOutCallbackHandler
from langchain_community.callbacks import WandbCallbackHandler
import wandb
# Initialize monitoring
wandb.init(project="langchain-production")
# Custom callback for metrics
class MetricsCallbackHandler(AsyncCallbackHandler):
def __init__(self):
self.start_time = None
self.token_count = 0
self.cost = 0.0
async def on_chain_start(self, serialized, inputs, **kwargs):
self.start_time = time.time()
async def on_chain_end(self, outputs, **kwargs):
duration = time.time() - self.start_time
wandb.log({
"chain_duration": duration,
"token_count": self.token_count,
"estimated_cost": self.cost
})
async def on_llm_new_token(self, token: str, **kwargs):
self.token_count += 1
# Monitored chain
monitored_chain = chain.with_config(
callbacks=[
MetricsCallbackHandler(),
WandbCallbackHandler(),
StdOutCallbackHandler()
]
)
Set up performance tracking:
from prometheus_client import Counter, Histogram, start_http_server
# Prometheus metrics
chain_requests = Counter('langchain_requests_total', 'Total chain requests', ['chain_name', 'status'])
chain_duration = Histogram('langchain_duration_seconds', 'Chain execution duration')
class PrometheusCallbackHandler(AsyncCallbackHandler):
def __init__(self, chain_name):
self.chain_name = chain_name
self.start_time = None
async def on_chain_start(self, serialized, inputs, **kwargs):
self.start_time = time.time()
async def on_chain_end(self, outputs, **kwargs):
duration = time.time() - self.start_time
chain_duration.observe(duration)
chain_requests.labels(chain_name=self.chain_name, status='success').inc()
async def on_chain_error(self, error, **kwargs):
chain_requests.labels(chain_name=self.chain_name, status='error').inc()
# Start metrics server
start_http_server(8000)
7. Production Deployment and Scaling
Deploy LCEL chains with FastAPI:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
app = FastAPI(title="LangChain LCEL API")
class QueryRequest(BaseModel):
question: str
session_id: str = "default"
class QueryResponse(BaseModel):
answer: str
metadata: dict
@app.post("/chat", response_model=QueryResponse)
async def chat_endpoint(request: QueryRequest):
try:
result = await conversational_chain.ainvoke(
{"input": request.question},
config={"configurable": {"session_id": request.session_id}}
)
return QueryResponse(
answer=result,
metadata={"session_id": request.session_id, "model": "gpt-3.5-turbo"}
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
return {"status": "healthy", "timestamp": time.time()}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
Kubernetes deployment configuration:
# k8s-langchain-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: langchain-api
spec:
replicas: 3
selector:
matchLabels:
app: langchain-api
template:
metadata:
labels:
app: langchain-api
spec:
containers:
- name: api
image: your-registry/langchain-api:latest
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: langchain-secrets
key: openai-api-key
- name: REDIS_URL
value: "redis://redis-service:6379"
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1000m"
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: langchain-service
spec:
selector:
app: langchain-api
ports:
- port: 80
targetPort: 8000
type: LoadBalancer
💡 Scaling tip: Use horizontal pod autoscaling based on CPU/memory usage and implement connection pooling for database and vector store connections.
LCEL: The Future of LangChain Development
LangChain Expression Language (LCEL) represents a paradigm shift in building AI applications, providing a declarative syntax for composing complex chains. LCEL enables developers to create maintainable, testable, and scalable AI workflows.
Key benefits for production deployments:
Composability: Build complex workflows from simple, reusable components
Streaming support: Native streaming for real-time applications
Async operations: Built-in support for concurrent and parallel processing
Type safety: Better error handling and debugging capabilities
Migration path from legacy LangChain:
Identify existing chain patterns in your application
Refactor simple chains to LCEL syntax first
Implement streaming and async operations
Add monitoring and error handling
Deploy with proper scaling configuration
Key Takeaways
LCEL's pipe operator unifies prompt → model → parser flows into a single, readable line.
Compose runnables—sequential, parallel, and conditional—for clarity, speed, and smarter routing.
Achieve production reliability with fallbacks, retries, and comprehensive monitoring.
Use async streaming and batch APIs for low-latency, high-throughput workloads.
Deploy with FastAPI, containerize with Docker, and autoscale on Kubernetes for enterprise readiness.
Ongoing Maintenance Checklist
Monitor chain performance and token usage
Update LangChain and model versions regularly
Review and optimize chain composition patterns
Test streaming and async operations under load
Audit error handling and fallback mechanisms
Scale based on request patterns and latency requirements
Backup chain configurations and prompt templates
Monitor compliance with model provider rate limits
💡 Community engagement: Join the LangChain community discussions and contribute to the ecosystem. LCEL is actively developed with frequent updates and new features for production use cases.